




On January 30, 2024, in the middle of the day (in the US), Apple’s iCloud services experienced an outage that prevented users from using the iCloud.com website or the popular iCloud Mail service. According to some reports, Apple Pay services may also have been impacted.
This is another example of how downtime can impact any web service—even a tech giant. This is another opportunity for IT professionals responsible for website reliability and performance to learn and improve.
In this article, we’ll explore what happened to iCloud services on January 30, 2024, and we’ll look at three key takeaways for IT Ops and website administrators.
Scope of the outage
The iCloud outage reports began surfacing around noon (Eastern time) on January 30, 2024. Apple reported the incident was resolved at 4:38 p.m. The incident impacted iCloud mail and storage users, which have hundreds of millions of users. Based on multiple down reports across the internet, it’s unclear if everyone was affected by the outage, but many were.

iCloud users faced messages like this during the January 30, 2024 outage.
Unfortunately for the tech giant, this outage followed the Apple Music/iTunes outage, App Store issues, and Apple Pay and Apple Wallet maintenance, all of which hit in the week prior.
There were also reports during this iCloud outage that Apple Pay was affected, but we can’t confirm if those reports were related to the iCloud incident. Given this event took place several days after Apple Pay maintenance and the lack of firm confirmation that Apple Pay was part of this incident, we’ll consider Apple Pay out of the scope of this outage.
What was the root cause of the outage?
Apple hasn’t released a specific root cause for the iCloud outage, so we’ll put on our theoretical hats to do a root cause analysis. Here’s what we know or can reasonably assume:
- The incident impacted many (maybe all) iCloud users.
- Most other Apple services were unaffected.
- Other platforms/services at Apple had maintenance within several days prior to the incident.
- Apple recovered from the iCloud incident within about four hours.
Considering these circumstances, we can think of several potential root causes. Here are our top three:
- Infrastructure issues: Given the problems and maintenance with other Apple services in the days before the incident, it’s probable that an infrastructure-related issue caused the iCloud outage. Alternatively, it could have been as simple as a configuration issue.
- Change-induced failures: Changes to SaaS services are common, but that doesn’t mean they come with zero risk. It’s possible a minor update or planned change had unintended consequences, bringing iCloud services down.
- Dependency failures: When a third-party service fails or changes, it can also create an outage. We saw this in our review of the Chase/Zelle outage, where an issue impacted Zelle users on Chase’s side.
What can we learn from the outage?
While we might not all operate at the scale of Apple, we can still learn valuable lessons from incidents like the iCloud outage. With our armchair root cause analysis in mind, let’s explore what teams can learn from the incident.
Lesson #1: Go beyond ping.
Ping is an excellent tool. We like it so much, it’s in our name. However, the ICMP protocol that powers ping can only go so far. If your monitoring only checks ping responses, you will likely miss outages that impact user experience. This isn’t just a challenge with ping; the same can be said for monitoring that only checks for successful TCP or UDP connections.
In many cases, a web server may respond to ping or accept network connections but still be down from an end-user perspective. For example, a server might return an HTTP error code instead of a 2xx response. Alternatively, a page might load but display incorrect or malformed content.
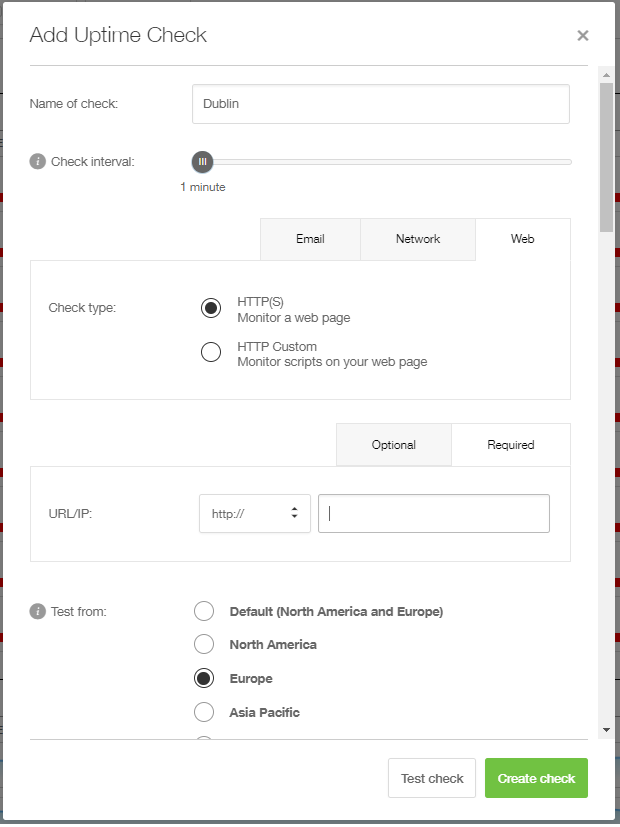
Creating an uptime check in Pingdom and selecting a probe location.
Additionally, just because your site is accessible from one place doesn’t mean it’s working for all your users. Someone on the East Coast might be able to access your site without issue, while users on the West Coast experience issues due to a content delivery network (CDN) problem.
Detecting these more nuanced outages requires the correct type of monitoring. At Pingdom, we use different types of checks to help solve this problem. However, regardless of the tool you use, the key is to monitor in a way that reflects how users interact with your site or service.
Lesson #2: Monitor your dependencies.
Modern web-based services have complex dependencies that can lead to an outage—even if your systems are functioning correctly. An offline IDP or SSO service could prevent users from authenticating to your site. Similarly, services like Twilio or Mailchimp going offline could break an app’s notification services even if the rest of your app is working fine.
This is another area where the right checks can be helpful. At a minimum, ensure you have a check that covers all your critical dependencies from an end-to-end workflow perspective. For example, monitor the user’s login journey to ensure users can reliably authenticate to your site. Synthetic monitoring is a great way to create “transactions” that mimic these types of user journeys and help you stay one step ahead of outage reports.
Lesson #3: Empower your power users.
Apple has a vast user community. During the iCloud outage, the user community helped clarify the issue while Apple engineers addressed the problem. On Apple’s support community discussion site, users in the know quickly informed other users of an active known issue based on Apple’s System Status page (example threads here, here, and here).
This sort of self-service within the Apple community has several benefits, including:
- Reduced confusion among end users
- Fewer support inquiries about the incident
- Less “noise” for engineers, so they can focus on solving the problem
Likely, your own services don’t have a user base as broad as Apple’s. However, power users can help set you up for success when an incident occurs. To get this right, try to establish the following:
- A group of power users for your application. If you provide an app or service outside of your organization, there is a good chance you have some external power users. These are the people who know your app’s ins and outs and pay attention to the details.
- A forum for those power users to help others. Whether you use something your brand controls directly (such as a Zendesk community) or an external platform like Reddit, X (formerly Twitter), or Facebook, establish an online forum for your power users to help others. This will enable your services to benefit from your power users’ willingness to help.
- A source of truth power users can reference. Knowledge-based articles can help solve basic “how to” challenges, making it easy for your power users to solve common questions from newbies. However, when an incident occurs, your users will need up-to-date information they can count on. Status pages are the go-to solution for those cases.
How Pingdom can help
SolarWinds® Pingdom® is a simple, powerful, and extensible website monitoring platform designed to help IT Ops teams proactively approach incident response. With support for various connectivity checks from locations around the globe, synthetic and real user monitoring (RUM), and detailed reports, Pingdom empowers digital teams to improve their uptime without a steep learning curve.
If you’d like to take Pingdom for a test drive, sign up for a free (no credit card required) 30-day trial today.


