





On July 25, 2023, Chase Bank customers who use the Zelle payment network experienced an outage that lasted for nearly a day. The outage came months after a headline-grabbing outage involving Zelle and Bank of America in January 2023. What is interesting about these Zelle outages is that they provide us with some high-profile examples of the risks and challenges of services with complex dependencies. They also offer a useful case study on the importance of “mean time to innocence” (MTTI) from a technical (not blame!) perspective.
In this post, we’ll take a closer look at the outage, gleaning three key takeaways for teams responsible for infrastructure uptime and end-user experience.
Scope of the outage
The Chase/Zelle outage lasted nearly a day, impacting Zelle transactions initiated by Chase customers. Given the nature of Zelle, this outage directly impacted end users’ ability to conduct financial transactions in the middle of a work week.
Here’s a breakdown of the associated timeline of events:
- The incident began around 10 a.m. ET on Tuesday, July 25, 2023.
- Zelle tweeted in the early afternoon that the issue was with Chase, not the Zelle payment network.
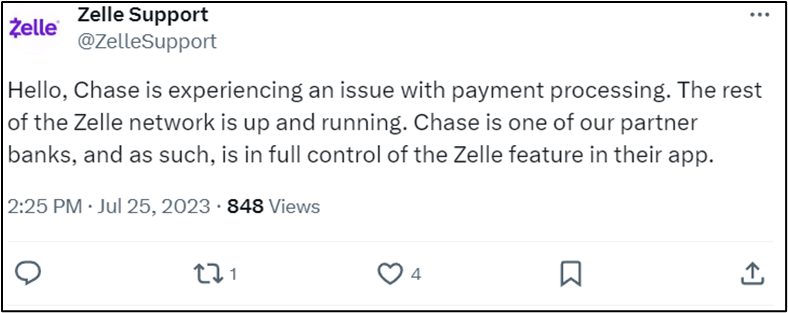
- The incident was still unresolved at 10 p.m. but reports of issues on Downdetector had reduced significantly by this time.
- Complaints continued into Wednesday, July 26, 2023, but the outage seemed to be resolved that day.
- Chase confirmed no other services were affected.
What was the root cause of the outage?
Chase and Zelle both acknowledged that the issue was on Chase’s side. Chase did not identify the underlying cause, but we can rule out Zelle infrastructure and external networks with this information.
Peter Tapling, a former Early Warning executive, and Richard Crone, CEO of Crone Consulting LLC, were quoted in a related Yahoo! Finance article offering insight into how the combination of modern payment-processing services and legacy banking systems may have led to the outage. Tapling noted that modern payment infrastructure like the Federal Reserve’s FedNow and The Clearing House Real-Time Payments (RTP) typically have network-level resilience. However, core banking infrastructure isn’t typically as modern. It’s also not easy to upgrade or replace.
That means that modern peer-to-peer (P2P) payment apps like Zelle have a lot going on under the hood that could fail. In addition to the standard complexities in maintaining a high-traffic, distributed system, a Zelle transaction also depends on the availability of bank data. If any of the pieces involved in checking balances, validating information, or completing the transaction fails, the system is effectively “down” from the perspective of the end user.
What can we learn from the outage?
This outage is a helpful case study in MTTI, dependencies, and communication. Even if you don’t work in fintech, there are plenty of valuable insights to consider. Let’s consider our top three takeaways from the incident.
Takeaway #1: Map your dependencies
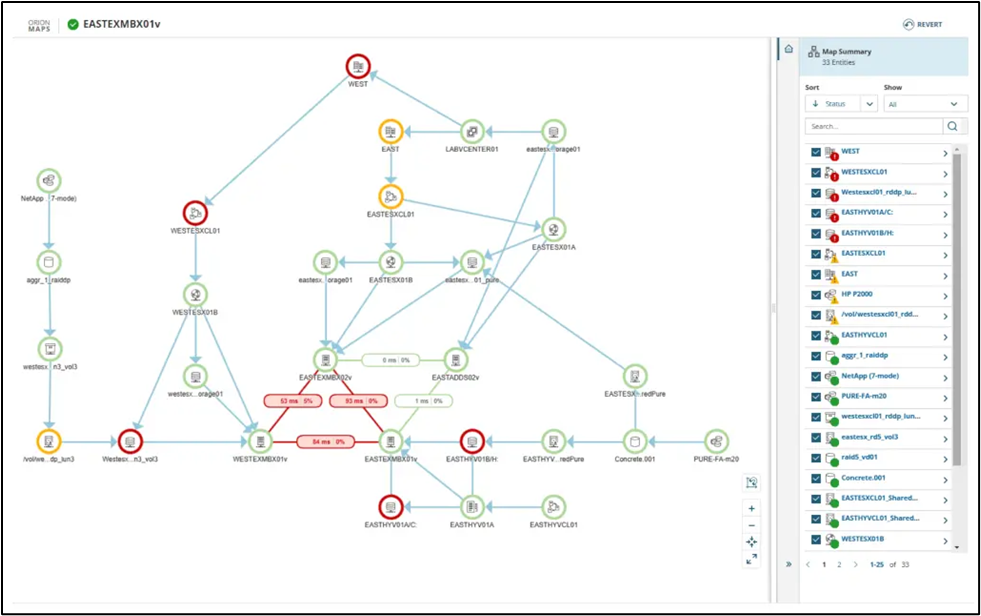
An application dependency map from SolarWinds® Server & Application Monitor (SAM).
In the world of payment processing, where decades-old backend systems and modern payment networks all come together to reconcile a transaction, dependencies can create unexpected failures and debugging challenges. While massive payment networks have unique nuances, the issue of dependency risk isn’t exclusive to fintech.
Even in a relatively simple, modern web application, the end user experience may involve dependencies on components such as:
- Web server (such as Apache or Nginx)
- A database
- An identity provider
- Network connectivity
- A content delivery network (CDN)
To mitigate risk and enable effective troubleshooting, teams should map all the dependencies involved in delivering service to an end user. Additionally, your monitoring strategy should account for behavior from the end user’s perspective. If your end users are in Los Angeles, uptime measured from Chicago or New York won’t mean much.
Takeaway #2: Get to (technical) “mean time to innocence” quickly
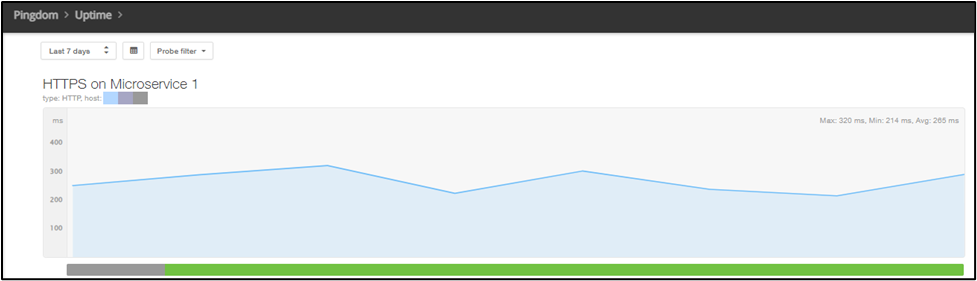
A graph of an HTTPS check in Pingdom®.
For a brand in the payments industry where trust and reliability are essential, it’s easy to understand why Zelle wanted to clarify that the issue was NOT with their network. Given that Chase owns part of Zelle’s parent company, Early Warning Services, maybe even Chase was incentivized to make that clear.
Nonetheless, finger-pointing isn’t a sound site reliability engineering or infrastructure management practice. So, you won’t see us advocating for blaming a person or team. However, identifying a problem’s technical root cause is an essential aspect of incident response and service restoration.
From that perspective, MTTI is critical. Incident responders need to leverage variable isolation to understand where to focus their energy and restore service. That starts with clear indicators of current service health.
Synthetic monitoring with checks of specific protocols, transaction monitoring that mimics specific user journeys, and status pages can be beneficial here. If a check is “green”, responders can quickly move on to the next suspect service or component to continue troubleshooting.
Takeaway #3: Design out large-scale failures
A silver lining during the outage was that only Chase users were affected, and Zelle payments were the only affected feature. That means the overall system and interconnections between services were designed to limit the impact of this incident to a relatively narrow scope. While that didn’t help the affected users directly, it does mean that the overall negative impact was isolated.
It also means there were potential workarounds for users during the outage, such as using a different transfer method or a different bank. While these workarounds certainly aren’t ideal, they’re better than nothing.
Teams looking to learn from this outage should consider how they can design their systems to reduce the blast radius of any particular system failure. Ideally, this should emerge naturally in a microservices architecture that embraces loose coupling, but that isn’t always true. Accounting for variables such as network connections, cloud providers, and DNS can also be tricky.
To ensure you’re balancing risk and effort appropriately, be intentional about understanding dependencies, potential failure modes, and acceptable downtime. Then, test your assumptions. Wherever practical, reduce the risk of one system failure causing another system to go offline. To ensure you’re being realistic with your assumptions, consider leveraging chaos engineering to inject faults and see what breaks in a test environment.
How Pingdom can help
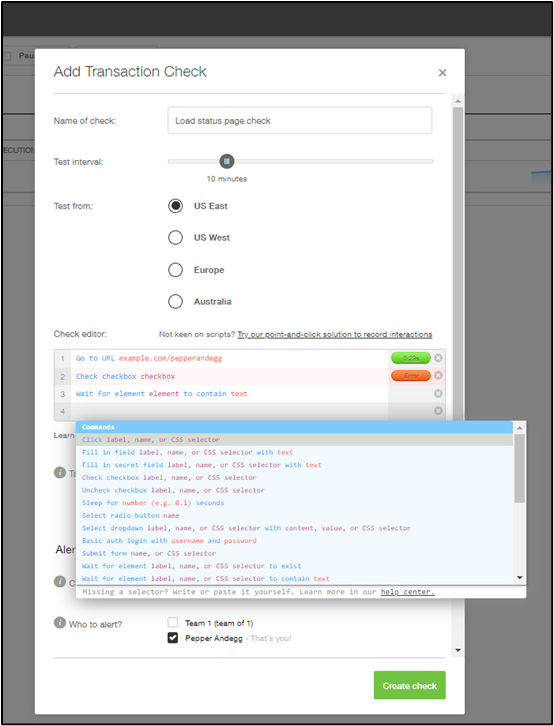
Creating a transaction check in Pingdom.
Pingdom is a simple but powerful website monitoring tool that can help teams quickly understand the health of their web applications. With transaction monitoring, you can map out specific user journeys. And if they break, you can drill down fast. With monitoring from over 100 locations and support for multiple checks, Pingdom can help you reduce MTTI and MTTR, improve root cause analysis, and increase uptime and service quality in production.
To try Pingdom for yourself, claim your free 30-day trial today!


