





On August 27, 2023, CoffeeMeetsBagel (CMB)—a popular dating app—services went down in one of the more extensive outages of the year. Users couldn’t log in to the app, and services remained unavailable for over a week. Given CMB’s previous history of technical issues and the extent of the outage, the incident became a significant customer service fiasco for the company.
In this article, we’ll use CMB’s FAQ and other sources to unpack the outage details. Then, we’ll look at three key takeaways you can learn from the incident to help improve your infrastructure monitoring and business processes.
Scope of the outage
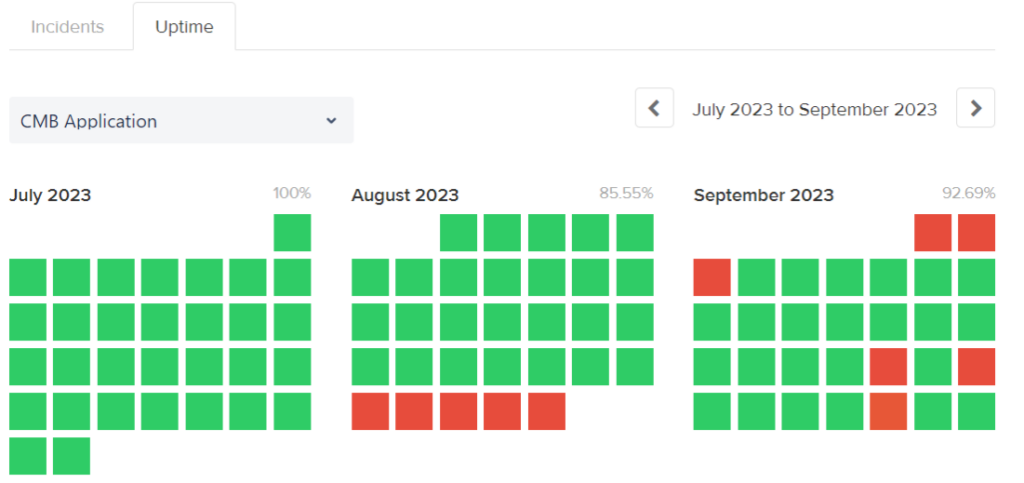
The CoffeeMeetsBagel status page shows the outage started in the last week of August 2023. (Source: CoffeeMeetsBagel)
According to the CoffeeMeetsBagel status page, the outage began on August 27, 2023, and lasted just over a week until September 3, 2023. During the outage, users could not sign in or use the application. While we don’t have a precise count of users affected, CMB hit 10 million users in 2019, so the impact of the downtime was certainly not narrow.
The immediate effect of the outage was CMB users being unable to use the app to find a match and set up dates. For several days after the outage, issues such as missing chats, fewer “bagels” in the matching system, and missing “boosts” remained. During and after the outage, users took to forums like Reddit to complain, inquire about status, and discuss alternatives to the platform.
Additionally, recent history fueled the fire of customer concerns about application reliability and security. The dating site had been impacted by previous headline-grabbing events, such as a 2019 data breach, so user frustration was compounded by concerns the app has had too many technical challenges.
Root cause of the outage
A threat actor deleted CMB data and files. While we don’t have all the details, this was clearly an incident caused by a malicious actor rather than a system failure, a configuration error made by a legitimate user (such as Facebook’s 2021 outage), or a vaguely defined “technical issue” (like Instagram’s 2023 outage).
According to Himalayas, the dating service uses multiple languages and frameworks, including Python, PHP, Go, and Java. It also stores data with Redis, PostgreSQL, Cassandra, and other popular services. Of course, an application can tie those different components together in many ways that a threat actor could exploit. Unfortunately, it’s not clear from the information available exactly how CMB systems were compromised in this case.
Based on the official FAQ stating CMB “quickly re-established a secure environment for [its] technology team to restore [its] production service,” it seems plausible a threat actor compromised an account or service critical to maintaining CMB production services.
What can you learn from the outage?
The CMB outage is another opportunity for IT teams to learn from incidents that impact other organizations. Here are three key takeaways from the outage you can use to improve your processes and uptime.
Lesson #1: Emphasize all phases of the incident response life cycle
The NIST incident response life cycle phases. Source: NIST SP 800-61R2
Incidents like the CMB outage remind us to review incident response basics like the incident response life cycle. Using NIST’s Computer Security Incident Handling Guide as a reference, the phases of the life cycle are:
- Preparation
- Detection and analysis
- Containment, eradication, and recovery
- Post-incident activity
During the CMB outage, the recovery aspect of the life cycle was where users felt the most pain. For an app with millions of users, a week of service disruption is crippling. Teams should ensure they can quickly restore services if an incident takes them offline. Or, to put it another way: Test your backup and recovery plan!
Of course, what qualifies as a “quick” restoration of services is fuzzy. That’s where thinking deeply about your recovery time objectives (RTOs) and recovery point objectives (RPOs) comes into play.
Additionally, effective detection can reduce the time a threat actor has to do damage. For effective detection, organizations turn to tools such as:
- Anti-malware software
- Intrusion detection systems (IDS)
- Intrusion prevention systems (IPS)
- Endpoint detection and response (EDR)
- Real-user monitoring (RUM)
- Synthetic monitoring (SM)
- Observability solutions
While detection and recovery often drive headlines, it’s also important to execute well in the other life cycle phases. Root cause analysis and lessons-learned exercises are common post-incident activities that can drive organizational changes to reduce the risk of repeat issues. Similarly, activities in the preparation phase—like training, simulations, and vulnerability scans—can help teams mitigate risks before a threat actor exploits them.
Lesson #2: Store (or don’t store!) data wisely
Fortunately, no payment data was compromised during the CMB outage. In part because the dating platform uses third-party payment processes and does not store payment data. Using a secure third party is often an easy decision for businesses that need to accept payments online.
However, there is a more general lesson here: Storing data comes with a risk proportional to the data’s sensitivity.
Organizations operate in an environment where data is the new gold. As a result, storing sensitive data can lead to increased negative impact in the event of a breach. Reduce the risk of sensitive data exposure by ensuring your teams are intentional about data classification and retention. To take the intentionality even further, determine if there is data your organization doesn’t even need to store in the first place.
Lesson #3: Make it right with your users
If you’re running a business, things will occasionally go wrong. How you engage your users after an incident is just as important as how you handle the incident itself. In the case of CMB, the company provided active premium and mini subscribers with a free 14-day extension to compensate for the outage. Ideally, this helped CMB retain some users who would have otherwise walked away.
Another way to make it right with your users is to be transparent in your communications. Looking at comments in posts like this on the CMB subreddit related to the incident, we see tech-savvy and highly invested users particularly want your transparency, and they can often be the loudest voices of discontent. Despite CMB being a dating site, commenters call out site reliability engineering and web development issues as they speculate on the root cause.
If you have a highly technical user base, then remember their expectations for your communication during an outage may be higher than the average consumer. Here are a few ways you can boost transparency during and after an outage:
- Maintain a status page and update it every four hours or less.
- Let users know if their data was compromised.
- Explain what happened and what you’re doing to prevent it in the future.
How Pingdom can help
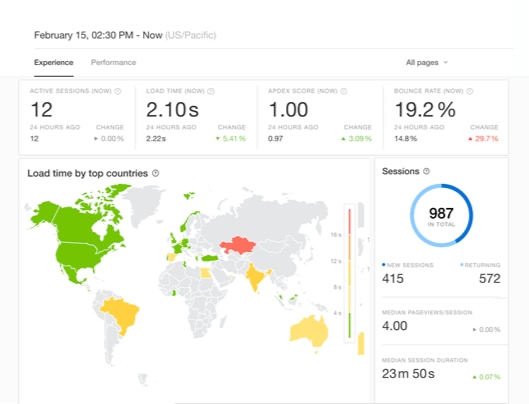
A real-user monitoring (RUM) experience dashboard in Pingdom. (Source)
SolarWinds® Pingdom® is a simple and scalable end-user experience monitoring platform that enables teams to detect problems so they can respond to them quickly. With Pingdom, you can monitor services from over 100 locations using synthetic and real-user monitoring. In the event of an extended outage, Pingdom’s public status page makes it easy for teams to provide users with up-to-date information about service status.
To try Pingdom for yourself, claim your free 30-day trial today!

